
Du kennst das bestimmt: Die Informationen sind im Unternehmen vorhanden, aber niemand findet sie. Wichtige Dokumente schlummern in unstrukturierten Team-Ordnern, kritisches Wissen steckt in E-Mail-Postfächern und über verschiedene Projektlaufwerke hinweg existieren unzählige Versionen einer einzigen Datei. Für Mitarbeiter ist dieser Zustand frustrierend und ineffizient. Für eine künstliche Intelligenz ist er eine Sackgasse.
Viele Unternehmen versuchen, dieses Problem mit Retrieval-Augmented Generation (RAG) zu lösen, um ihr internes Wissen für KI-Anwendungen nutzbar zu machen. Doch oft merken sie schnell: Der klassische Ansatz reicht nicht aus. Die Antworten der KI bleiben vage, sind veraltet oder verletzen im schlimmsten Fall interne Zugriffsrechte.
Inhaltsverzeichnis
Die wichtigsten Erkenntnisse vorab:
- Klassisches RAG stößt im Unternehmen an Grenzen: Ansätze wie reiner Upload oder die Anbindung per MCP/Federated Search scheitern oft an fehlenden Metadaten, veralteten Informationen und unzureichender Rechteverwaltung. Die Folge sind ungenaue oder unsichere KI-Antworten.
- Contextual RAG schafft eine verlässliche Wissensbasis: Eine zentrale Kontext-Ebene bündelt und verknüpft Informationen aus allen angebundenen Systemen. Sie reichert Daten mit wichtigem Kontext wie Nutzerrollen, Projekten, Zeitstempeln und Quellenvertrauen an.
- Mehr als nur Daten – mehr Kontrolle und Relevanz: Statt nur mehr Daten in ein KI-Modell zu laden, sorgt die Kontext-Ebene dafür, dass die richtigen Informationen zur richtigen Zeit genutzt werden. Das erhöht die Präzision, senkt Risiken und macht KI-Anwendungen erst wirklich produktionsreif.
- Die Basis für leistungsstarke KI-Agenten: Eine saubere Kontext-Ebene ist die Grundlage für KI-Agenten für Unternehmen, die nicht nur einfache Aufgaben, sondern komplexe, mehrstufige Prozesse zuverlässig automatisieren sollen.
Dieser Artikel zeigt Dir, warum eine zusätzliche Kontext-Ebene – das Prinzip hinter Contextual RAG – der entscheidende Faktor ist, um KI im Unternehmen nicht nur zu testen, sondern sie produktionsreif, sicher und skalierbar zu machen. Es geht darum, die Kontrolle zurückzugewinnen und aus Datenchaos handlungsrelevantes Wissen zu formen.
Das Problem: Unternehmenswissen ist da – aber nicht nutzbar
Das Kernproblem in den meisten Unternehmen ist nicht ein Mangel an Wissen, sondern dessen chaotische Verteilung. Informationen liegen in Silos vor, die nicht miteinander kommunizieren:
- Dokumenten-Silos: SharePoint, Netzlaufwerke, Confluence und lokale Festplatten.
- Tool-Wildwuchs: Unterschiedliche Abteilungen nutzen verschiedene Tools für ähnliche Aufgaben.
- Fehlender Kontext: Wer hat ein Dokument erstellt? Für welches Projekt ist es relevant? Ist es die finale Version oder ein veralteter Entwurf?
- Komplexe Berechtigungen: Nicht jeder Mitarbeiter darf alles sehen. Zugriffsrechte sind oft verschachtelt und schwer nachzuvollziehen.
Dieses Chaos führt dazu, dass wertvolles Wissen ungenutzt bleibt und die Zusammenarbeit erschwert wird. Eine effektive Wissensmanagement-Lösung muss genau hier ansetzen.
Was klassisches RAG leistet – und wo es scheitert
Klassisches RAG versucht, dieses Problem zu umgehen, indem es externe Datenquellen für ein Sprachmodell zugänglich macht. Anstatt nur auf seinem trainierten Wissen zu basieren, kann das Modell Informationen aus einer angebundenen Datenbank oder einem Dokumenten-Index abrufen. Die zwei gängigsten Ansätze haben jedoch gravierende Nachteile im Unternehmenskontext.
Relevanz- & „Chunk“-Probleme
Beim Upload-basierten Ansatz werden Dokumente auf eine Plattform geladen, in kleine Teile zerlegt („Chunks“) und indexiert. Dabei geht jedoch entscheidender Kontext verloren. Metadaten wie Autor, Gültigkeitsdatum oder die Beziehung zu einem Projekt werden oft nicht oder nur inkonsistent übernommen. Die KI hat keine Möglichkeit zu bewerten, wie vertrauenswürdig oder aktuell eine Information ist. Sie findet zwar Keywords, versteht aber nicht deren Bedeutung im Gesamtkontext.
Aktualität, Versionierung, Berechtigungen
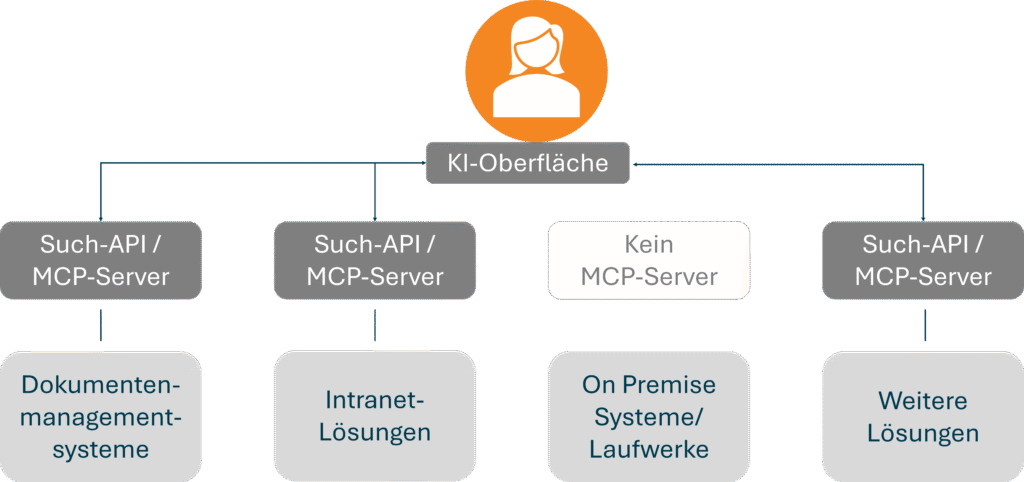
Der zweite Ansatz ist die Systemanbindung per MCP (Model Context Protocol) oder Federated Search. Hier wird die Suchanfrage an das Quellsystem (z.B. die SharePoint-Suche) delegiert. Das klingt einfach, schafft aber neue Probleme:
- Abhängigkeit: Die Qualität der KI-Antwort hängt vollständig von der Suchqualität des angebundenen Systems ab. Auf Ranking, Relevanzbewertung oder Fehlerbehandlung hat die KI-Plattform kaum Einfluss.
- Fehlender Kontext: Wichtige Kontextinformationen wie das Nutzerprofil, laufende Projekte oder die bisherige Interaktionshistorie lassen sich kaum in Echtzeit einbeziehen.
- Rechte & Sicherheit: Zugriffsrechte werden oft nur unzureichend geprüft. Im schlimmsten Fall erhält ein Nutzer Informationen, die er nicht sehen dürfte.
Beide Ansätze führen dazu, dass die KI mit unpassenden oder unsicheren Informationen gefüttert wird, was die Qualität der generierten Antworten drastisch senkt.
Du möchtest einen besseren Ansatz ausprobieren? Dann teste jetzt amber. amber setzt auf Contextual RAG und hilft dir, das unternehmensinterne Wissen skalierbar anzubinden.
Was „Contextual RAG“ anders macht (Kontext-Ebene als System)
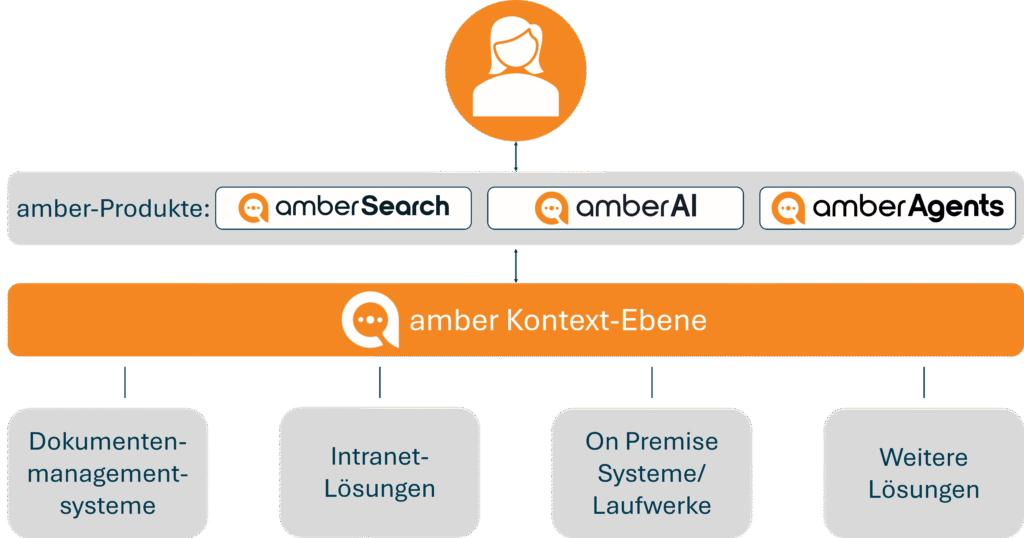
Contextual RAG geht einen entscheidenden Schritt weiter. Anstatt sich auf die lückenhaften Suchfunktionen der Quellsysteme zu verlassen, baut es eine eigene, zentrale Kontext-Ebene auf. Man kann sie sich wie ein intelligentes Gedächtnis des Unternehmens vorstellen, das alle Informationen systemübergreifend zusammenführt und in Beziehung setzt. Diese Ebene ist das Herzstück einer modernen Enterprise-Search-Lösung.
Signale: Rechte, Rolle, Projekt, Zeit, Quelle, Vertrauen
Diese Kontext-Ebene modelliert nicht nur die reinen Daten, sondern auch die entscheidenden Signale, die deren Relevanz bestimmen:
- Metadaten: Wer ist der Autor? Wann wurde etwas erstellt? Zu welchem Projekt gehört es?
- Zugriffsrechte: Wer darf auf welche Information zugreifen? Dies wird auf Basis von Access Control Lists (ACLs) rollen- und objektbasiert sichergestellt.
- Beziehungen & Ereignisse: Ein Ticket im Service-Desk referenziert ein technisches Dokument im DMS. Ein Commit in der Entwicklung löst eine Review aus. Diese Verknüpfungen sind entscheidend, um Prozesse zu verstehen.
Kontext-Ranking statt „nur Retrieval“
Anstatt nur eine simple Keyword-Suche durchzuführen, nutzt Contextual RAG diese Signale, um die Relevanz von Informationen zu bewerten. Die KI erhält nicht einfach eine Liste von Dokumenten, sondern eine gewichtete und kontextualisierte Auswahl der besten Informationsquellen. Das Ergebnis sind präzisere, relevantere und sicherere Antworten.
MCP ist nicht der Wissensspeicher
In diesem Zusammenhang ist es wichtig, die Rolle des Model Context Protocol (MCP) richtig einzuordnen. MCP ist ein nützliches Protokoll, um KI-Modellen den Zugriff auf externe Tools und Aktionen zu ermöglichen. Es ist jedoch kein Wissensspeicher und löst auch nicht das Relevanzproblem. Wenn Du mehr über die Grundlagen erfahren möchtest, findest Du hier eine verständliche Erklärung: „MCP verständlich erklärt“.
MCP = Aktionen/Tools; Kontext-Ebene = Wissen/Relevanz/Steuerung
Die Stärke von MCP liegt darin, Aktionen auszulösen: „Lege ein neues Ticket an“, „Sende eine E-Mail“, „Trage einen Termin in den Kalender ein“. Die Kontext-Ebene hingegen liefert das Wissen und die Steuerung, die für diese Aktionen notwendig sind. Sie beantwortet die Frage: „Welche Informationen sind für diese Aufgabe relevant, aktuell und vertrauenswürdig?“
Ein System, das sich nur auf MCP verlässt, um Wissen abzufragen, läuft Gefahr, die falschen Entscheidungen auf Basis unvollständiger Informationen zu treffen. Mehr zu den Risiken und Grenzen von MCP kannst du hier nachlesen: „4 Nachteile von MCP“.
Beispiel-Szenarien
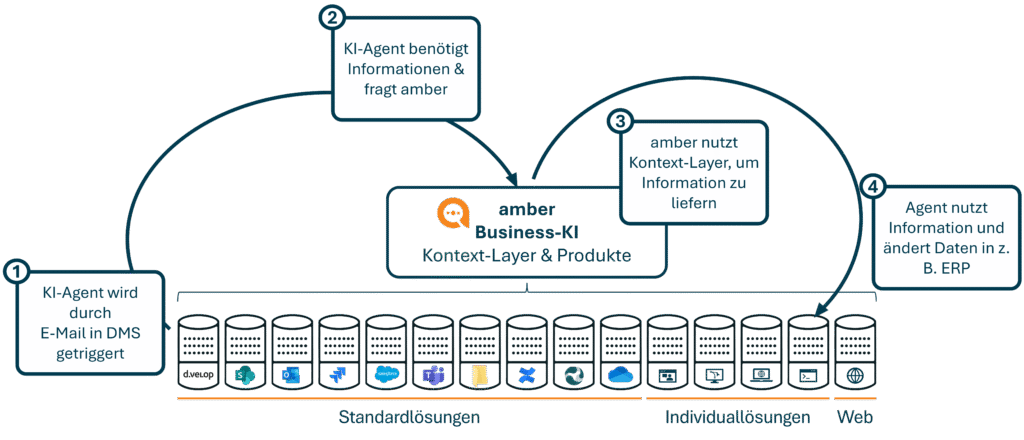
Wie sieht der Vorteil von Contextual RAG in der Praxis aus? Hier sind drei konkrete Beispiele:
R&D/Projekt: Spezifikation finden
Eine Projektleiterin sucht die finale technische Spezifikation für ein Bauteil, das vor zwei Jahren entwickelt wurde. Eine klassische Suche liefert Dutzende Versionen. Die Kontext-Ebene hingegen identifiziert das Dokument als „final“, verknüpft es mit dem abgeschlossenen Projekt und berücksichtigt, dass die Projektleiterin die entsprechenden Zugriffsrechte hat. Sie erhält sofort die richtige Datei.
Service: Ticket schneller lösen
Ein Servicemitarbeiter erhält ein Ticket zu einem seltenen Fehler. Die Kontext-Ebene erkennt die Fehlerbeschreibung und verknüpft sie automatisch mit einem ähnlichen, bereits gelösten Fall aus dem letzten Jahr sowie mit dem zugehörigen internen Entwickler-Ticket in Jira. Der Mitarbeiter muss nicht selbst suchen und kann das Problem in Minuten statt Stunden lösen.
Vertrieb: Angebotswissen aus CRM + DMS
Ein Vertriebsmitarbeiter erstellt ein Angebot für einen Kunden. Die Kontext-Ebene zieht sich automatisch die relevanten Informationen aus dem CRM (bisherige Kommunikation), dem DMS (gültige Preislisten) und dem Projektmanagement-Tool (verfügbare Ressourcen). Das Angebot ist schneller erstellt, fehlerfrei und basiert auf den aktuellsten Daten.
Checkliste: So erkennst du, ob du eine Kontext-Ebene brauchst
- [ ] Sind Informationen über viele verschiedene Systeme und Laufwerke verteilt?
- [ ] Fällt es Mitarbeitern schwer, die „eine richtige“ Version eines Dokuments zu finden?
- [ ] Gibt es komplexe Zugriffsrechte, die bei der Informationssuche berücksichtigt werden müssen?
- [ ] Sollen KI-Anwendungen nicht nur chatten, sondern echte, wissensbasierte Aufgaben erledigen?
- [ ] Ist die Qualität und Verlässlichkeit von KI-Antworten für dein Unternehmen geschäftskritisch?
Wenn du mehrere dieser Fragen mit „Ja“ beantwortest, ist eine Kontext-Ebene für dich unverzichtbar.
Deine nächsten Schritte
Der Umstieg auf eine KI-gestützte Arbeitsweise ist mehr als nur die Einführung eines neuen Tools. Er erfordert eine solide Architektur, die Ordnung ins Wissenschaos bringt. Contextual RAG mit einer zentralen Kontext-Ebene ist der Schlüssel, um das volle Potenzial von KI sicher und skalierbar zu heben.
Bist du bereit, aus totem Wissen handlungsrelevante Intelligenz zu machen?
Entdecke in einer persönlichen Demo, wie ambersearch mit einer intelligenten Kontext-Ebene dein Unternehmenswissen zugänglich macht und KI-Prozesse produktionsreif gestaltet.
FAQs zu Contextual RAG
1. Was ist Contextual RAG?
Contextual RAG ist eine Weiterentwicklung des klassischen Retrieval-Augmented Generation (RAG ). Anstatt nur Daten abzurufen, baut es eine zentrale Kontext-Ebene auf. Diese Ebene reichert Informationen aus verschiedenen Unternehmenssystemen mit Metadaten, Zugriffsrechten und Beziehungen an, um der KI präzisere, relevantere und sicherere Antworten zu ermöglichen.
2. Was ist der Unterschied zu klassischem RAG?
Klassisches RAG ruft oft unstrukturiert Informationen ab und leidet unter fehlendem Kontext. Es kann nicht zuverlässig bewerten, ob eine Information aktuell, relevant oder für den Nutzer freigegeben ist. Contextual RAG löst dieses Problem durch eine intelligente Kontext-Ebene, die wie ein zentrales Unternehmensgedächtnis fungiert und die Qualität der KI-Antworten entscheidend verbessert.
3. Warum sind Berechtigungen und Compliance bei RAG so kritisch?
In Unternehmen dürfen nicht alle Mitarbeiter auf alle Informationen zugreifen. Ein klassisches RAG-System, das Berechtigungen ignoriert, stellt ein enormes Sicherheits- und Compliance-Risiko dar. Es könnte vertrauliche Daten an unbefugte Personen weitergeben. Eine Kontext-Ebene stellt sicher, dass die KI die Zugriffsrechte bei jeder Anfrage strikt einhält.
4. Welche Datenquellen sind typisch für eine Kontext-Ebene?
Eine Kontext-Ebene integriert typischerweise eine Vielzahl von strukturierten und unstrukturierten Datenquellen. Dazu gehören Microsoft 365 (SharePoint, Teams, Outlook), Netzlaufwerke, Dokumentenmanagementsysteme (DMS), CRM-Systeme wie Salesforce, Kollaborationstools wie Confluence und Jira sowie branchenspezifische Fachanwendungen.
5. Wie ergänzt das Model Context Protocol (MCP) eine Kontext-Ebene?
MCP ist ein Protokoll, das es einer KI ermöglicht, Aktionen in anderen Systemen auszuführen (z.B. „erstelle ein Ticket“). Die Kontext-Ebene liefert das dafür notwendige Wissen und die Entscheidungsgrundlage (z.B. „welche Informationen gehören in dieses Ticket?“). MCP ist also für die Ausführung zuständig, während die Kontext-Ebene für das Wissen und die Relevanz sorgt. Die beiden Technologien ergänzen sich ideal.